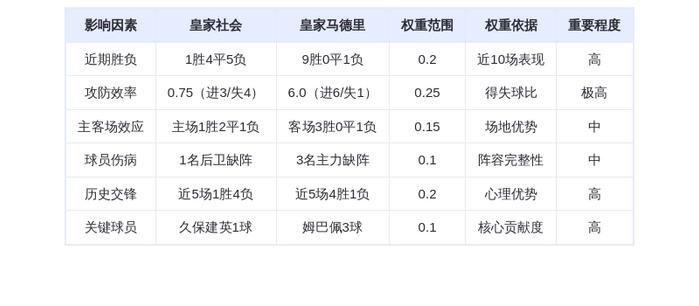
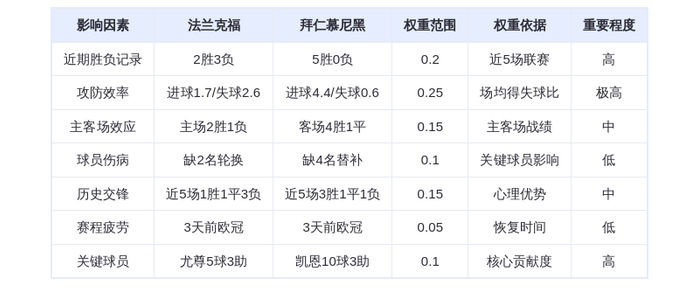
Deepseek R1 推理实测:4 块英伟达 GB300 能干 16 块 H1
IT之家援引博文介绍,CoreWeave 使用 Deepseek R1 推理模型,对比评估英伟达 Blackwell 架构 GB300 NVL72 和上一代 H100 GPU 的差别。归功于英伟达升级架构,增强内存和带宽,测试结果显示,GB300 在仅使用 4 块 GPU 的情况下,即可完成原本需要 16 块 H100 才能运行的任务。
GB300 NVL72 平台支持高达 37TB 的内存容量(最高可达 40TB),并配备每秒 130TB 的内存带宽。该平台为减少 GPU 间数据分割次数deepseek,采用 4 路并行设计,并通过 NVLink 和 NVSwitch 高速互连提升通信效率。
CoreWeave 指出,这不仅是 FLOPs 算力的提升,更是系统架构在实际业务场景下的效率跃迁。对于需要运行复杂模型的企业客户,GB300 NVL72 提供了更高的扩展性和更低的延迟,帮助他们更快、更经济地部署和运行 AI 服务。原文出处:Deepseek R1 推理实测:4 块英伟达 GB300 能干 16 块 H100 的活,感谢原作者,侵权必删!